
Bu yazımızda Java’nın tarihi gelişimini, günümüzde bulunduğu yeri, mikroservis mimarilere uyumunu ve GraalVM, LLVM ve Quarkus’un nasıl alternatifler yarattığından bahsedeceğiz.
1. Neden Java
Java yaklaşık 20 yıl önce ilk defa ortaya çıktığında büyük bir probleme çözüm getirme vaadiyle yazılımcıların dikkatini çekmişti. Vaat şuydu, bir yazılımcı farklı mimarilere sahip donanımların nasıl çalıştığını bilmesine gerek kalmayacaktı. Ve bütün bu ortamlar için ayrı ayrı kod yazmayacak, tek kod tüm ortamlarda çalışabilecekti. Bunu “Write once, run anywhere” mottosuyla ifade ettiler. Derlenen kod JVM ismi verilen bir sanal makine üzerinde çalıştırılacaktı. Bu sayede geliştiriciler işletim sistemi, donanım ve benzeri ortamsal farklılıklardan etkilenmeyecekti.
2. Günümüzde Java
Java’nın sağladığı bu esneklik dönemin de şartları göz önünde bulundurulduğunda yazılım geliştiricilerin en tercih ettiği yazılım dillerinden birisi olmayı başardı. Peki halen bu şekilde mi devam ediyor? Bunun için güncel dillerin popülaritesi ile ilgili bir araştırma yaptım. Bu araştırmayı yaparken araştırma şirketlerince yapılan anketlerin taraflı olabileceği düşüncesini de dikkate aldım. Karşıma çıkan ve en tarafsız olduğunu hissettiğim çalışma Redmonk tarafından 2019 Q1’de yapılmıştı. Stack Overflow ve Github’daki popülerlikler üzerinden yapılan çalışmanın grafiği aşağıdaki gibi:
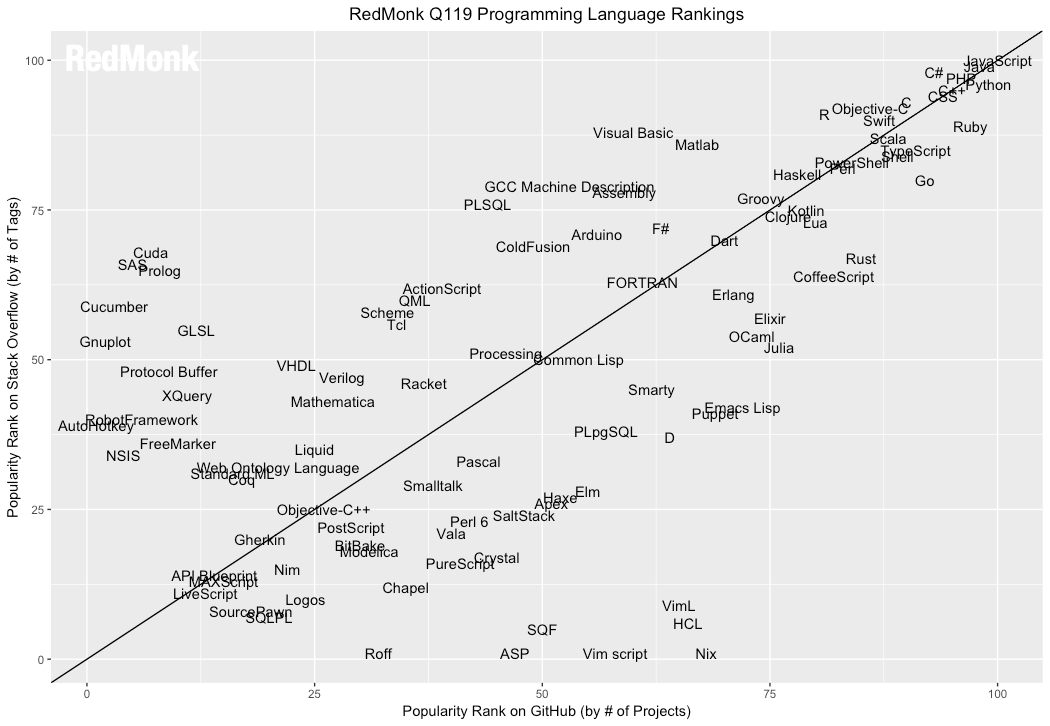
Görünüşe göre Java halen en popüler dillerden birisi olarak hayatına devam ediyor. Peki Java bunu nasıl başarıyor?
İlk günden bu yana Java yazılım diline Java Specification Request (JSR) ismi verilen yeni özellikler Java Community Process (JCP) tarafından belirli standartlar gözetilerek eklendi. Functional Programming, Nonblocking I/O gibi popüler yazılım geliştirme paradigmaları da benzer şekilde dile kazandırıldı. Peki dil evrimine devam ederken JVM’de neler yaşandı? En önemli JVM fonksiyonlarından birisi olan garbage collection işlemini sağlayan yapılarda optimizasyonlar, yenilikler yapıldı. Özellikle Java11 ile birlikte gelen Z Garbage Collector (ZGC) ile büyük yenilikler hayatımıza dahil oldu. Valhalla Project gibi kuluçka projelerle alternatif sanal makine başarımları geliştirilmeye devam ediyor. Hayat çok güzel, her şey yolunda, sistem tıkır tıkır işliyor değil mi? Peki gerçkten öyle mi?
3. Java ve Mikroservisler
Mikroservisler hayatımıza girdiğinden bu yana Docker gibi Mesos gibi container teknolojilerini çok daha yoğun kullanmaya başladık. En basitinden Dev/Prod Parity’yi sağlamayabilmek için bu tarz bir teknolojiyi kullanmak şart oldu. Şu anda güçlü bir uygulamada beklediğimiz özellikler; her an erişilebilir, dirençli, düşük gecikmeye sahip, hızlı ve reaktif olmaları.
Kubernetes gibi bir orchestration aracıyla yönettiğimiz clusterlarımızda sanallaştırma teknolojilerini kullanarak bir çok esneklik kazanıyoruz. Geliştirdiğimiz kodlarımız, Kubernetes deploymentlarında bir base image’dan yarattığımız custom image’lar içerisinde çalışıyor. Bu image’ların içerisinde işletim sistemi kaynakları ve kütüphaneler bulunuyor ve kodumuz bunların yardımıyla ekstra bir kaynağa gerek kalmadan çalışabiliyor.
Son birkaç cümle aslında bugünkü yazımızın çıkış noktasını oluşturuyor. Bir kez daha irdeleyelim.
“Uygulamamıza ait kodlar, ihtiyaç uyduğu işletim sistemi kaynakları ve harici kütüphaneler ile birlikte tek bir image’ın içerisinde paketlenebilir; bir container olarak herhangi bir yerde çalıştırılabilir.”
Yukarıdaki cümleye bakılırsa herhangi bir yerde çalıştırılabilmesi cümlesi ile eğer containerized bir ortamınız mevcut ise Java’nın senelerdir en güçlü yanı olarak tanıttığı özelliğe artık ihtiyacınız olmadığı yorumunu doğuruyor. Bu noktada sorulması gereken soru şu; Java her yerde çalışabilmek uğruna nelerden vazgeçiyor? Her yerde çalışabilme gibi bir derdi olmasaydı neler daha farklı olabilirdi? Neler daha performanslı çalışırdı, paket boyutlarında ne gibi değişiklikler söz konusu olurdu?

Yazılan Java kodunun farklı işletim sistemlerinde, mimarilerde çalışabilmesi için aslında hatrı sayılır şeylerden feragat edilmesi gerekmektedir. Derlenmiş kodumuzun çalıştırılmasından sorumlu Java Runtime Environment’da(JRE) bu sebepten çok fazla kaynak ve kod bulunmaktadır. Örneğin OpenJDK’nın base image’ı 250MB’dan daha büyüktür. Şirketler genellikle mikroservis mimariye uygun kod geliştirebilmek için Spring teknolojilerini kullanarak kod geliştirdiği varsayımı ile ilerlersek kodumuzun çalışabildiği containerın boyutu en azından yaklaşık 450–500MB’lar civarında olacaktır. Bu boyutlar disposability prensibinden dolayı tercih etmediğimiz bir durumdur. Çünkü büyük boyutlardaki containerların ayağa kalkması uzun sürmektedir. Peki ne yapabiliriz? Sırtımızdaki yükten nasıl kurtulabiliriz?
3.1. Just in Time (JIT) vs Ahead of Time (AOT) Compilers
Bu noktada derleyiciler hakkında daha detaylı bilgi paylaşmam gerekiyor. Derleyiciler yazılan kodun işlemcinin anbladığı makine koduna çevrilmesinden sorumlu yapılardır. Derleyicileri kabaca iki gruba ayırmak mümkün; **Just in Time** **(JIT)** ve **Ahead of Time (AOT)** derleyiciler.
3.1.1. Ahead of Time (AOT)
**AOT Derleyiciler;** yazılan kodun doğrudan spesifik olarak donanımın anladığı makine koduna çevrilmesinden sorumlu derleyicilerdir. C/C++ gibi diller bu derleyicileri kullanmaktadır.
3.1.2. Just in Time (JIT)
**JIT Derleyiciler;** çalışma esnasında toplanan performans metrikleri aracılığıyla uygulanan derleme tekniğini kullanan derleyicilerdir. Uygulama ayağa kalkarken interpreted modda bytecode’u satır satır yorumlar. Bu esnada da kodun sık kullanılan kısımları hakkında istatistik toplar. Uygulamanın sık çalıştırılan kısımları belirlenir. Bu kısımlar bytecode’dan makine koduna çevrilir. Bu sayede kodun doğrudan CPU üzerinde çalıştırması mümkün olur. Bu işlemlere **Native Direct Operations** ismi verilir, JVM bu operasyonları çalıştırırken **Native Register Machine** olarak çalışmaktadır. Kodun sıcak alanları sürekli istatistiklerle izlenerek bu optimizasyon sürekli devam eder. Java bu derleyicileri kullanmaktadır.
AOT ve JIT derleyicileri kıyaslamaya gelince, JIT derleyiciler platform bağımsız çalışmaktadır. AOT derleyiciler bu açıdan derlendiği platforma bağımlıdır. Ancak AOT daha hızlıdır, çünkü doğrudan işlemcinin anlayacağı şekilde derlenmiştir.
4. GraalVM
GraalVM Oracle tarafından geliştirilen bir sanal makine. Java, JVM tabanlı diğer diller, Javascript, Ruby, Python, R, C/C++ ve diğer [**Low Level Virtual Machine(LLVM)**](https://llvm.org/) desteği sağlayan dilleri farklı deployment senaryolarında çalıştırabiliyor. LLVM sayesinde adaptörünü yazdığını herhangi bir dili de GraalVM’de çalıştırmak mümkün. Bu yapısıyla polygot mimariler’e tam uyum sağlamaktadır. Ayrıca bellek ve GC optimizasyonları noktasında daha verimli çalıştıklarını iddia ediyorlar, Twitter’ı GraalVM üzerinde çalıştırıyorlarmış.
GraalVM kullandığı JIT derleyicisinin daha performanslı olduğu iddiasına sahip. Ancak bu yazıda odaklandığımız yeteneği daha çok **native image** yaratabiliyor olması. Native image, özetle Java tabanlı dillerle AOT kullanabilmek anlamına geliyor. Yani JIT derleyici kullanmadan tamamen optimize bir native base image’a özel kodumuzun derlenmesi ve bu imaj üzerinde çalışması mümkün oluyor.
Sırtımızdaki yükten nasıl kurtulacağız dediğimiz sorumuzu hatırlarsınız. İşte GraalVM bizim için bu noktada kurtarıcı olarak ortaya çıkıyor. Doğrudan makine koduna derlenmiş kodlar sayesinde uygulamanın açılışı hızlı gerçekleşecek. Ve çalışması esnasında yapılan istatistik toplama, optimizasyon için runtimeda yapılan HotSpot derlemeler vb tüm süreçlerden bizi kurtaracak. Bunların yanında kodun tam performans çalışabilmesi için gereken JVM’in ısınma süresi(istatistik toplama vs hotspot derlemelerin aldığı zaman) tarih oluyor, kod çok hızlı bir şekilde ayağa kalkarken yüksek performansla doğrudan çalışmaya başlıyor. Hayat çok güzel değil mi :)
4.1. Gerçekten Sihirli Değnek Mi?
GraalVM bir önceki başlıkta sunulan her şeyi sunuyor. Ancak native image kullanacaksanız bir kısıtımız var. Zaten dikkatli gözler farketmiştir. Native image runtime’da sürpriz sevmez! Nasıl çalışacağı runtime’a çıkmadan önce net olarak tanımlanmış kodlar ancak optimize edilebilir ve makine koduna çevrilebilir. Yani özetle, native image kullanacaksanız reflection kullanamazsınız!
4.2. Ya Spring Boot?
Bildiğiniz gibi Spring, Inversion of Control (IoC) prensibi ile çalışmaktadır. Diğer adıyla Dependency Injection (DI) olarak bildiğimiz yapıda tanımladığımız singleton Spring Bean’leri ApplicationContexttarafından preload edilir ve runtime’da ne zaman getBean() metodu çağırılırsa lazy loading ile BeanFactory tarafından bean örneği yaratılır. Bütün bu süreçte de bildiğiniz gibi reflection kullanılmaktadır :) Yani eğer native image kullanma düşüncesindeyseniz çalışma mantığını düşündüğümüzde Spring bunun için uyumlu bir seçenek olmayacaktır. Spring ile native image kullanmayı sağlamak için farklı projelere rastlayabilirsiniz, şu an için verimli bir çözüm olmamakla birlikte belki de çözüm için farklı alternatifleri düşünmenin vakti gelmiştir, ne dersiniz?
5. Quarkus

Red Hat’in sponsor olduğu Quarkus Projesi’nin mottosu “Supersonic Subatomic Java”. Kendisini Kubernetes Native Java geliştirimi için GraalVM ve OpenJDK HotSpot VM’lerini destekleyen ve en iyi Java kütüphanelerinden ve standartlarından oluşan bir birleşim olarak tanımlıyor. Dilerseniz imperative dilerseniz reactive kod geliştirimi yapabilirsiniz. Reactive kod geliştirimi büyük artılarından birisi.
AOT’nin çalışma yapısından bahsetmiştik, tam olarak da bu sebeplerden oluşan paket büyüklüğünün azalması ve hızlı şekilde ayağa kalkma öngörülerinin ölçümlerini kendi sitelerinde aşağıdaki görselle sunuyorlar.

Reflection kullanmayan bir kod yazacaksak bu teknolojilerden oluşan bir stack’e ihtiyacımız olacak. Quarkus’un belirli standartlar kapsamında birlikte yol ortağı olduğunu anasayfasında duyurduğu bazı teknolojiler Vert.X, Hibernate, RestEasy, Apache Camel, Eclipse Microprofile, Netty, Kubernetes, OpenShift, Jaeger, Prometheus, Kafka, Infinispan. Ayrıca extensions sayfasında ihtiyaç duyabileceğiniz geniş bir tool listesi mevcut.
6. Spring Boot vs Quarkus Testleri
Bazı rakamsal kıyasları yapmadan olmazdı. **JDK8** için OpenJDK ve GraalVM kullanarak testleri tamamladım. Quarkus için Get Started sayfasındaki yönendirmeleri izleyerek 0.20.0ve 0.19.1versiyonları için kodu geliştirdim. Spring Boot tarafında da 2.1.6releasinden Spring Initialzr üzerinden projeyi aldım. İki proje de birer rest uç açtım ve “Hello World” return ettim.
6.1. Startup Testi
6.1.1. Koşullar
İlk kıyasım minimum kaynak ile ayağa kalkma ve ayağa kalkış sürelerini ölçmek oldu. Oluşturduğum jar paketlerini çalıştırırken -Xmx parametresi ile memory kullanımını sıkıştırdım.
Spring projesi ayağa kalkabilmek için minimum 13MB belleğe ihtiyaç duydu. Bu minimum bellek ile ayağa kalkarken ayağa kalkış süresi yaklaşık 4–4,5 sn aralığında sürdü.
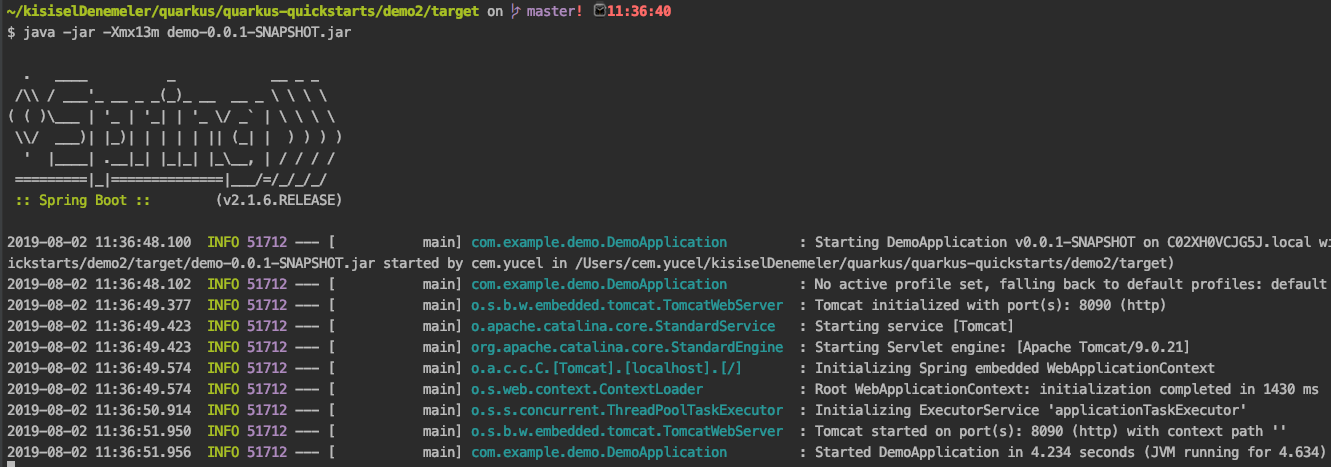
Aynı kaynakla (13MB) Quarkus projesini JIT derleyici ile HotSpot modda ayağa kaldırdığımda ortalama ayağa kalkma süresi 600ms civarlarında dolaştı.

Yine JIT derleyici ile Quarkus projesinin ayağa kalkabilmesi için ise minimum 7MB’lık bir memory yeterli oldu. Bu kaynakla ortalama ayağa kalkış süresi 1sn civarlarındaydı.

Açılış süresindeki asıl farkı gözlemlemek için Quarkus projesini AOT derleyici ile native derledim. Bu kez ayağa kalkış süresi şaşırtıcı şekilde çok daha hızlıydı. Ortalama 6–7ms’de ayağa kalkabildi.

6.1.2. Startup Testi Sonuç
Quarkus projesi Spring Boot projesine kıyasla daha az kaynakla çok daha hızlı ayağa kalkabildiğini gözlemledim. Eğer native derlerseniz bu süre misli şekilde kısalıyor.
6.2. Memory & CPU Testi
6.2.1. Koşullar
İkinci test senaryomda yaptıklarım memory’de heap alanına yapılacak aşırı yüklemelerde response süresinin nasıl etkilendiği ve belleğin, CPU’nun ve aktif thread sayılarının VisualVM üzerindeki görüntülerini kıyaslamak oldu.
Önce basit bir CPU yüklemesi, sonrasında da Elasticsearch’te barındırdığım 200MB’lık bir datanın çekilmesi senaryosu kurguladım. Bunun için iki projeye de aynı Elasticsearch low level rest client bağımlılığı ekledim. Rest uçlardan tetiklediğim iki uygulama yine http üzerinden Elasticsearch’ün rest uçlarından 200MB’lık datayı çektiği ve String’e çevirdiği anda ölçümümü sonlandırdım.
6.2.1.1. Spring Boot Memory & CPU

Ortalama 50MB heap ile açılan uygulama isteği aldığı anda yaklaşık 250 MB’lara ulaştı. Elastic’in took süresi 1sn idi. Network üzerindeki trafik sonlandığı ve tüm datanın uygulama üzerine bindiği anda maksimum kullanılan bellek 2,5GB’ları gördü. Uygulama açılışından itibaren ortalama 52 live thread ile tüm süreci yönetti ve 23 tane daemon thread vardı. Yaptığım 10 denemenin ortalaması tetikleme anından itibaren response’un String’e alınması ortalama 36sn sürdü.
Kod:
6.2.1.2. Quarkus Memory & CPU
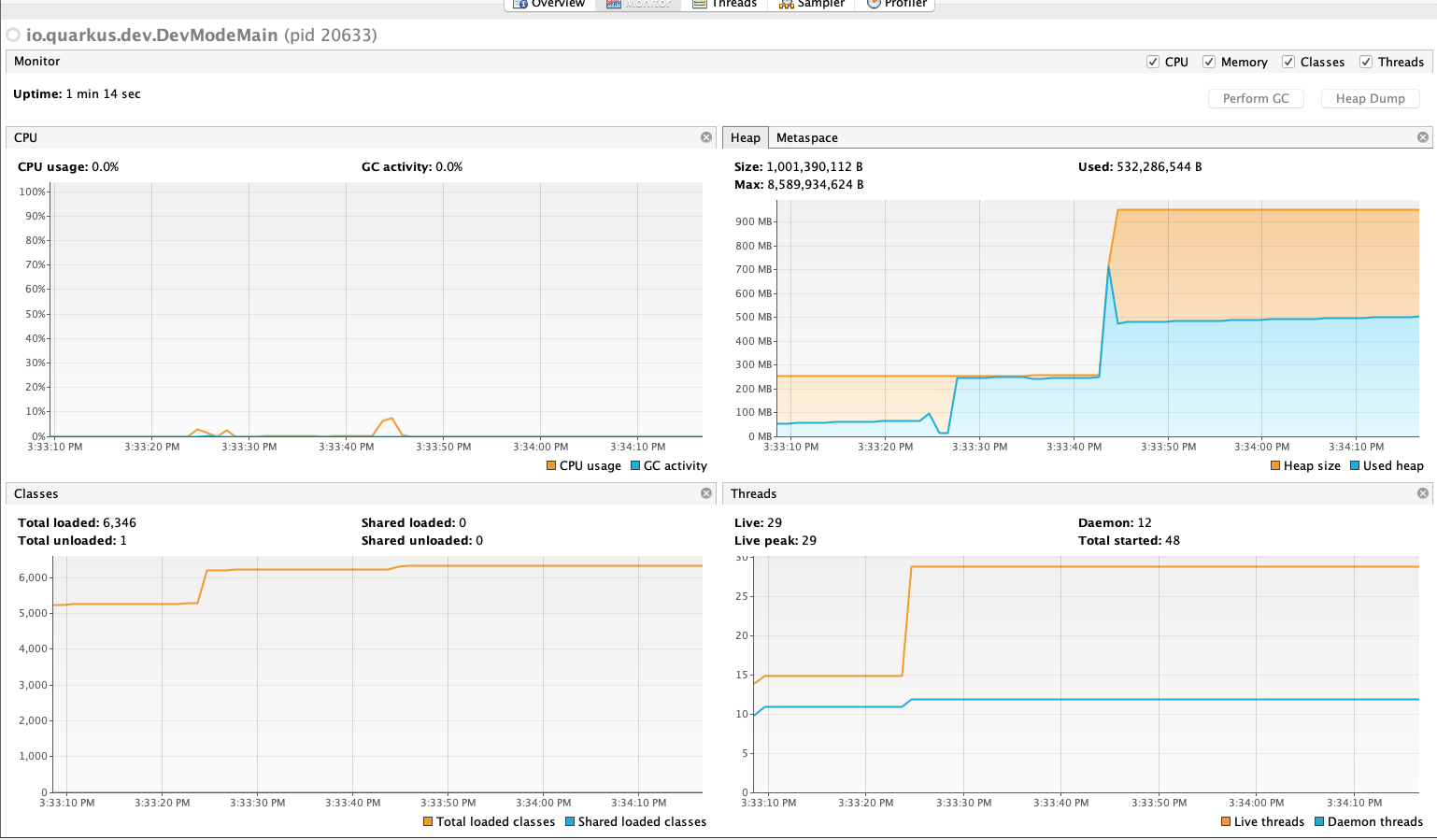
Ortalama 50MB heap ile açılan uygulama isteği aldığı anda yaklaşık 250 MB’lara ulaştı. Elastic’in took süresi 1sn idi. Network üzerindeki trafik sonlandığı ve tüm datanın uygulama üzerine bindiği anda maksimum kullanılan bellek 700MB’ları gördü ancak çok hızlı şekilde bu bellek alanını iade etti. 15 thread ile açılan uygulama istek anından itibaren ortalama 29 live thread ile tüm süreci yönetti ve 12 tane daemon thread vardı. Yaptığım 10 denemenin ortalaması tetikleme anından itibaren response’un String’e alınması ortalama 19sn sürdü.
Kod:
6.2.2. Memory & CPU Testi Sonuç
10ar denemenin sonucunda çıkan rakamlar tutarlılık gösteriyordu. Doğruyu söylemek gerekirse bu kadar bir farkı ben de beklemiyordum. Kafalardaki endişeleri yok etmek için kodları da yukarıya ekledim. Aşağıdaki tabloyu özetlemek gerekirse native olarak çalışan Quarkus kodu Spring Boot koduna oranla hem zaman, hem memory hem de CPU açısından daha efektif sonuçlar doğuruyor.
7. Sonuç
Mikroservis mimariler ile uğraşıyorsanız optimizasyon, daha iyileştirme, daha az maliyetle daha fazla performans gibi konular için alternatif teknolojileri takip etmek ve deneyimlemek gerekiyor. Quarkus ve GraalVM bu teknolojilerden deneyimlemenin de ötesinde gelecek günlerde hayatımızın büyük birer parçası olacak gibi gözüküyor. Deneyimlemenizi şiddetle tavsiye ederim.