
Önceki yazımızda Kafka Streams’te KTable konusuna değinmiştik ve Kafka Streams’in cachelediği verileri belirli periyotlarda default storeu olan RocksDB’de nasıl tuttuğundan bahsetmiştik. Geçen yazıda dile getirmesem de RocksDB’de store ettiğimiz şey aslında okuduğumuz recordlara ait bir state. Bu ve bunun gibi başka verilerin özetlerini nasıl yönettiğimiz konusuna da bu yazımızda değineceğiz.
- Yazı: Kafka Streams Nedir
- Yazı: Kafka Streams KTable
- Yazı: Kafka Streams Stateful Operations
- Yazı: Kafka Streams Windowing

Logged-in eventlerinin basıldığı bir topic imizin olduğunu varsayalım. Hangi kullanıcı ne kadar kez login olmuş bu bilgiyi bir noktada saymak isteyebilirsiniz. Veya alışveriş merkezlerinin girişlerinde, yürüyen merdivenlerin başlangıcında lazerli bir hareket sensörü olduğu dikkatinizi çekmiştir. AVM’ye kaç kişi girdi, diğer katlara kaç kişi gitti, kat değişimi esnasında hangi yürüyen merdiven daha çok kullanıldı gibi bilgilerin sayımını yapmak ve mağaza kira fiyatlarına etki edebilecek bir istatistik toplamak isteyebilirsiniz. İşte bu bilgiler gelen recordların bazı operasyonlardan geçirilerek özetlerinin state olarak saklanması ile mümkün olabilir. Burada hatırlatmam gereken nokta, artık direk direk streame gelen recordlarla uğraşmıyoruz, bu recordları bir şekilde grupluyor ve bu gruplar üzerinde bir metadata üretiyoruz ve saklıyoruz. Kafka Streams 3 operasyonla(reduce, count ve aggregate) bu işlemi sağlıyor. Bu 3 operasyonun da dönüş tipi KTable’dır, dolayısı ile store işlemi bu şekilde sağlanmaktadır.
Reduce
Reduce operasyonunda yapılan işlem, gruplanmış recordlar için verilen fonksiyonun yerine getirilmesi ve bu metadatanın saklanmasıdır. Örnekle açıklayalım.
@Component
public class ReduceExample {
private static final Serde<String> STRING_SERDE = Serdes.String();
private static final String INPUT_TOPIC = "reduce-input-topic";
private static final String OUTPUT_TOPIC = "reduce-output-topic";
@Autowired
void buildPipeline(StreamsBuilder streamsBuilder) {
KStream<String, String> messageStream = streamsBuilder.stream(INPUT_TOPIC, Consumed.with(STRING_SERDE, STRING_SERDE));
Reducer<String> reducer = (String val1, String val2) -> val1 + val2;
messageStream
.peek((key, val) -> System.out.println("1. Step key: " + key + ", val: " + val))
.mapValues(val -> val.substring(3))
.peek((key, val) -> System.out.println("2. Step key: " + key + ", val: " + val))
.filter((key, value) -> Long.parseLong(value) > 1)
.peek((key, val) -> System.out.println("3. Step key: " + key + ", val: " + val))
.groupByKey()
.reduce(reducer)
.toStream()
.peek((key, val) -> System.out.println("4. Step key: " + key + ", val: " + val))
.to(OUTPUT_TOPIC, Produced.with(STRING_SERDE, STRING_SERDE));
}
}
Bir reducer yarattık ve topicten okuduğu eski değerlerin özeti ile yeni gelen değerin çıktısını birbirine concatenate edecek şekilde tanımladık. Input topicimize aynı key ile ardarda 3 value gönderdik.

Belirli bir süre geçtikten sonra uygulamamızın loglarına aşağıdaki satırlar düştü.
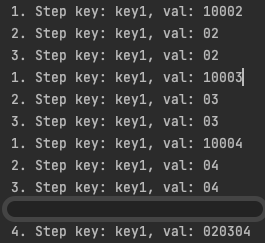
Output topic imizin çıktısı da 4. adımda oluşan reduce çıktısı gibi oldu.

Muhtemelen akla gelen soru, yeni gelen kayıtların son durumu ne olacak sorusu. Yani 10005, 10006 vb gönderirsem output topicine en baştan mı yoksa kalınan noktadan itibaren mi kayıt gelir.

Cevabı aşağıdaki gibi. Aslında cache ile store arasında bir fark bulunmuyor, sadece belirli periyotlarda bir emit ediliyor.

Aggregation
Aggregation aslında bir tür reducetur. Tek farkı, dönüş tipini farklı bir tip olarak ele alabilmemizdir. Örnek;
@Component
public class AggregationExample {
private static final Serde<String> STRING_SERDE = Serdes.String();
private static final Serde<Long> LONG_SERDE = Serdes.Long();
private static final String INPUT_TOPIC = "aggregation-input-topic";
private static final String OUTPUT_TOPIC = "aggregation-output-topic";
@Autowired
void buildPipeline(StreamsBuilder streamsBuilder) {
KStream<String, String> messageStream = streamsBuilder.stream(INPUT_TOPIC, Consumed.with(STRING_SERDE, STRING_SERDE));
Aggregator<String, String, Long> aggregator = (key, value, sum) -> Long.parseLong(value) + sum;
Initializer<Long> initializer = () -> 0L;
messageStream
.groupByKey()
.aggregate(initializer, aggregator, Materialized.with(STRING_SERDE, LONG_SERDE))
.toStream()
.to(OUTPUT_TOPIC, Produced.with(STRING_SERDE, LONG_SERDE));
}
}
Burada String,String olarak başladığımız streami bir aggregator aracılığıyla manipule edip String,Long’a çeviriyoruz. Başlangıç değerini alabilmesi için de bir Initializer tanımlıyoruz. Değerlerimizi gönderdiğimizde Long olarak dönüşmüş çıktımızı alıyoruz.


Count
Kullanımı yine basit, key bazında saydırma yapan fonksiyonun örneği de aşağıdaki gibi.
@Component
public class CountExample {
private static final Serde<String> STRING_SERDE = Serdes.String();
private static final Serde<Long> LONG_SERDE = Serdes.Long();
private static final String INPUT_TOPIC = "count-input-topic";
private static final String OUTPUT_TOPIC = "count-output-topic";
@Autowired
void buildPipeline(StreamsBuilder streamsBuilder) {
KStream<String, String> messageStream = streamsBuilder.stream(INPUT_TOPIC, Consumed.with(STRING_SERDE, STRING_SERDE));
messageStream
.groupByKey()
.count()
.toStream()
.to(OUTPUT_TOPIC, Produced.with(STRING_SERDE, LONG_SERDE));
}
}
Sorular
Aklınıza gelebilecek 2 sorunun yanıtını paylaşıp bu yazıyı sonlandıralım.
Emit gerçekleşmeden sunucum kapanırsa veya crash olursa bu kayıtların kaybedileceği anlamına mı geliyor? Tabii ki hayır çünkü en son yapılan emitin offset bilgisi saklanıyor.
Diğer soru, multi-instance çalıştığım durumda her instance taki storelar nasıl eşitlenecek? Yani 1. instanceın down olduğu bir anda 2. instance okumaya devam ederse 1. instance tekrar ayağa kalkınca neler olacak?
Aslında bu sonuçta ne elde etmek istediğinize göre değişen ve tercihlerimizi buna göre yapmamız gereken bir durum. Örneğin bir sayma işlemi yapıyorsanız, recordların geliş sırasının bir önemi yoksa aynı Kafka Consumer Group’taki n farklı instance ın toplam sonuca bir race condition yaratmayacağını öngörürüz. Sıralama önemli ise farklı maliyetlere katlanıp sıralamayı kaybetmemeyi sağlayabiliriz. Store’lar arasında eşitleme de yaratılan store için Kafka’nın arka planda yarattığı changelog topicleri ile garanti altına alınmaktadır.

Changelog topic inin çıktısı reducer örneğindeki output’a bastığımız nihai stream in çıktısı ile aynı.

Son yazımızda Windowing konusunu inceleyerek Kafka Streams yazı dizimizi tamamlayacağız.
Serinin diğer yazıları için
- Yazı: Kafka Streams Nedir
- Yazı: Kafka Streams KTable
- Yazı: Kafka Streams Stateful Operations
- Yazı: Kafka Streams Windowing
Projenin kodlarına buradan erişebilirsiniz.