
“Golang ile Uçtan Uca Proje Yapımı Serisi” 3. yazısında Go’da Merkezi Loglama Yönetimi nasıl yapılır sorusunun cevabını arayacağız. Ayrıca Access Log management için sonraki yazılarımızdan birisine atıfta bulunacağız. Merkezi loglama için 2 alternatif yöntem tasarlayacağız ve bunlar aşağıdaki gibi olacak.
- Filebeat + ELK Stack
- Kafka

Log yönetimi kritik bir konu. Live a kodunuzu aldınız ama performans problemi yaşıyorsunuz. Veya müşterilerinizden problem bilgileri geliyor ama siz hangi senaryoda ve nasıl gerçekleştiği hakkında bilgi sahibi değilsiniz. İşte bu noktalarda yaşayan kodunuzun sizinle iletişim kurabilmesinin en önemli yolu iyi yönetilen loglardan geçiyor.
Yüzlerce, binlerce mikroservisinizin olduğu bir senaryoda bir problem hakkında bilgi aramak samanlıkta iğne aramaya dönebilir. Her bir podun console una tek tek girip bakmak bir çözüm olamayacağı için logların merkezi bir noktadan takip edilebilmesi efektif bir çözüm olacaktır. Bu noktada Graylog, Splunk veya ELK Stack gibi çözümler iş görebilir.
Biz uygulamamızda uber-go/zap loglama frameworkünü kullanacağız. Örnek olarak 2 farklı yöntem izleyeceğiz. İlk yöntem podun üzerine/volume’una yazılan bir dosyayı Filebeat ile dinleyip Logstash aracılığı ile Elasticsearch’e indirip Kibana ile görselleştirmek. İkinci yöntem ise logları Kafka’ya indirmek ve sonrasında KafkaConnect gibi bir toolla istenen bir monitoring tooluna basılabilmesine uygun bir yapı tasarlamak. Burada kendi Kafka consumerınızı kodlayıp kendinize göre farklı alternatifler de gelitşirebilirsiniz. Biz KafkaDrop ile görselleştirerek 2. örneğimizi de tamamlayacağız.
Bu yöntemlerin seçilmesinin 2 temel nedeni var. İlki senkron loglama. Loglamanın senkron yapılması log kaybı riskini ortadan kaldırılması için kritik bir tercih, zaten Twelve Factor’ün önerisi bu yönde. Bu sebeple loglama, ana fonksiyonun zamanından çok çok kısa bir süre çalmak zorunda. Bunu sağlamak için logumuzu podun console’una yazarak ve veya üzerinde çalıştığımız diske logu bırakmak bir tercih olabilir. Veya put süresi çok çok düşük olan (nanosaniyeler mertebesinde) Kafka’yı bir event store olarak kullanabiliriz.
- sebebimiz de asenkron transfer. Senkron loglama yapılacak olan tool bir sebepten yavaşlarsa dalgalar halinde tüm microservicelerimiz bu yavaşlıktan etkilenmemesi için asenkron transfer faydalı olacaktır.
Kafka’nın HA & robust çalışması log kaybı ve gecikme riskini de minimalize etmesinden dolayı tercih edilebilir, sonrasında logların merkezi log aracına yönlendirmesi asenkron olarak yapılabilir. Diğer çözüm olan ELK yönteminde de Filebeat ile diskten okuyarak Logstash e paylaştığından asenkron çözüm oluşturmuş oluyor.
Filebeat + ELK Stack
İlk yöntemle başlayalım. NewLog ile log instance ı yaratımına ilk yazıda okuduğumuz konfigürasyonlarımızı alıyoruz.
Uygulamanın configlerinden alınan dosya ismiyle podun üzerine log bırakılacak şekilde bir yapılandırma yapıyoruz. Zap konfigürasyonunu kendi ihtiyaçlarınız doğrultusunda değiştirebilirsiniz, 24. satırda hazır production yapılandırmasını kullanarak devam ediyorum. Asıl konu bundan sonra başlıyor. Bu file logunu elastic’e kadar taşıyacak bir docker-compose oluşturuyoruz, init klasörü altında docker-compose-elk.yml ismiyle bulabilirsiniz.
Burada uygulamayı IDE’de test edebilmek için Filebeat’e logların yazılacağı /log klasörü için volume tanımı yaptım. Siz ihtiyacınız doğrultusunda bu configleri düzenleyebilirsiniz. Service-mesh inize sidecar olarak bağlayabilirsiniz.
Uygulamanın root dizininden aşağıdaki komutla docker-compose umuzu ayağa kaldırabiliriz.
docker-compose -f init/docker-compose-elk.yml up
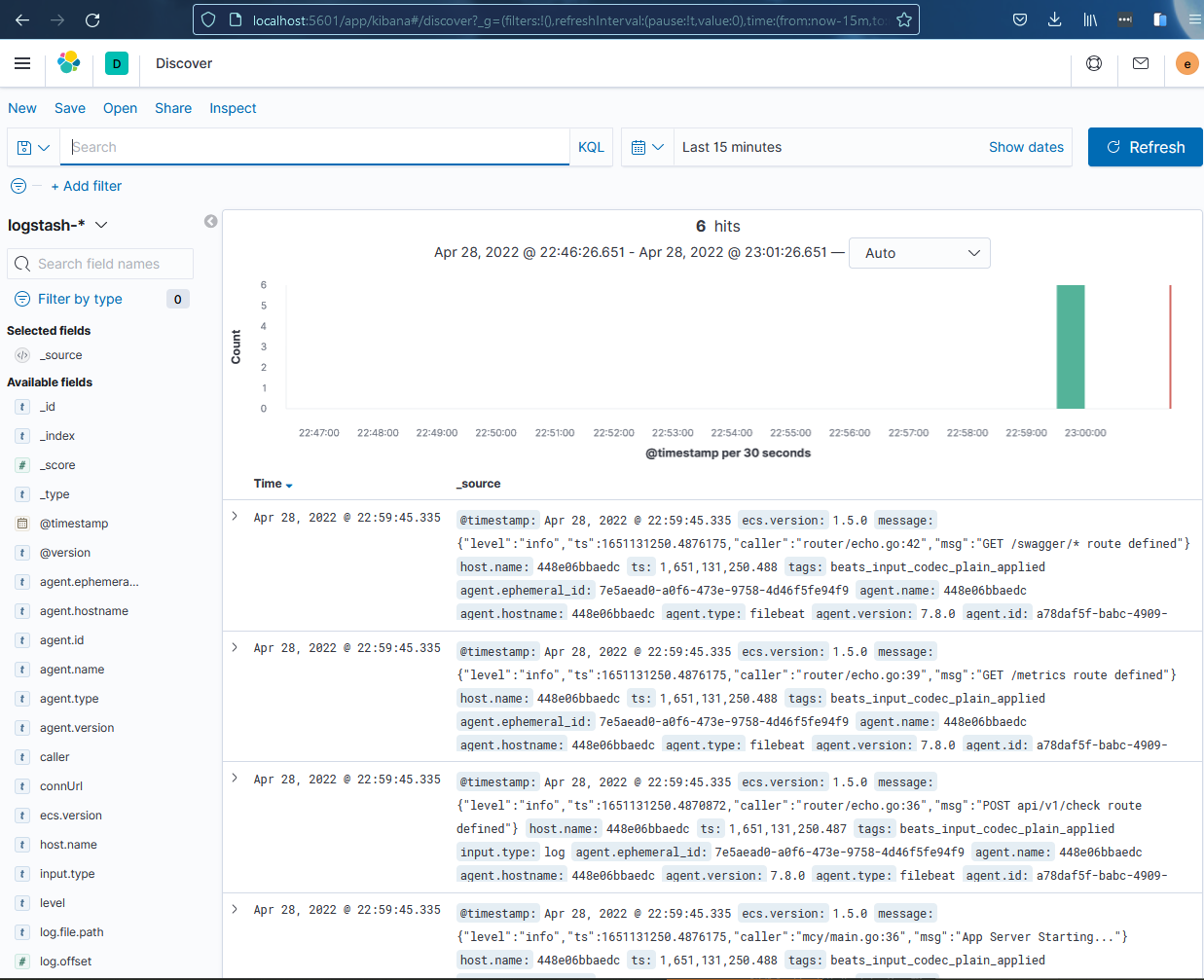
Başarılı şekilde ayağa kalktığında http://localhost:5601 ile elastic’in konsoluna düşebiliriz. elastic/changeme username passwordleri ile girdiğimizde bizden index in name pattern ini girmemizi isteyecek. Pattern olarak logstash-* olarak giriş yapıp index için de @timestamp seçerseniz Kibana>Discover altında tanımladığınız index üzerinden tüm loglarınıza erişebilmeye başlayacaksınız.
Kafka
2inci Alternatifimiz Kafka’ya logları basma örneğinde ise Zap logger a Kafka connector ı eklememiz lazım. Ancak hazır bir Kafka Sink bulunmadığı için kendimiz kodluyoruz.
Kafka’ya loglamanın nasıl yapıldığı ile ilgili bilgiye sonraki yazımızda değineceğiz. Bu yazıda sadece loglama kısmına odaklanıyoruz. KafkaSink’imizi yazdıktan sonra log.go dosyasındaki 13. satırı comment-outlayıp 12. satırı açtıktan sonra kodlarımız Kafka’ya senkron loglama yapmaya başlıyor. Bunun için init/docker-compose-kafka.ymlhazırlayıp bıraktım, içeriği şu şekilde.
Cluster olarak da ayağa kaldırabileceğiniz şekilde hazırladığım compose a tek bir Kafka ve onu gözlemleyebilmek için KafkaDrop servisini ekledim. Ayağa kaldırabilmek için yine projenin root dizininden aşağıdaki komutu çalıştırıyoruz.
docker-compose -f init/docker-compose-kafka.yml up
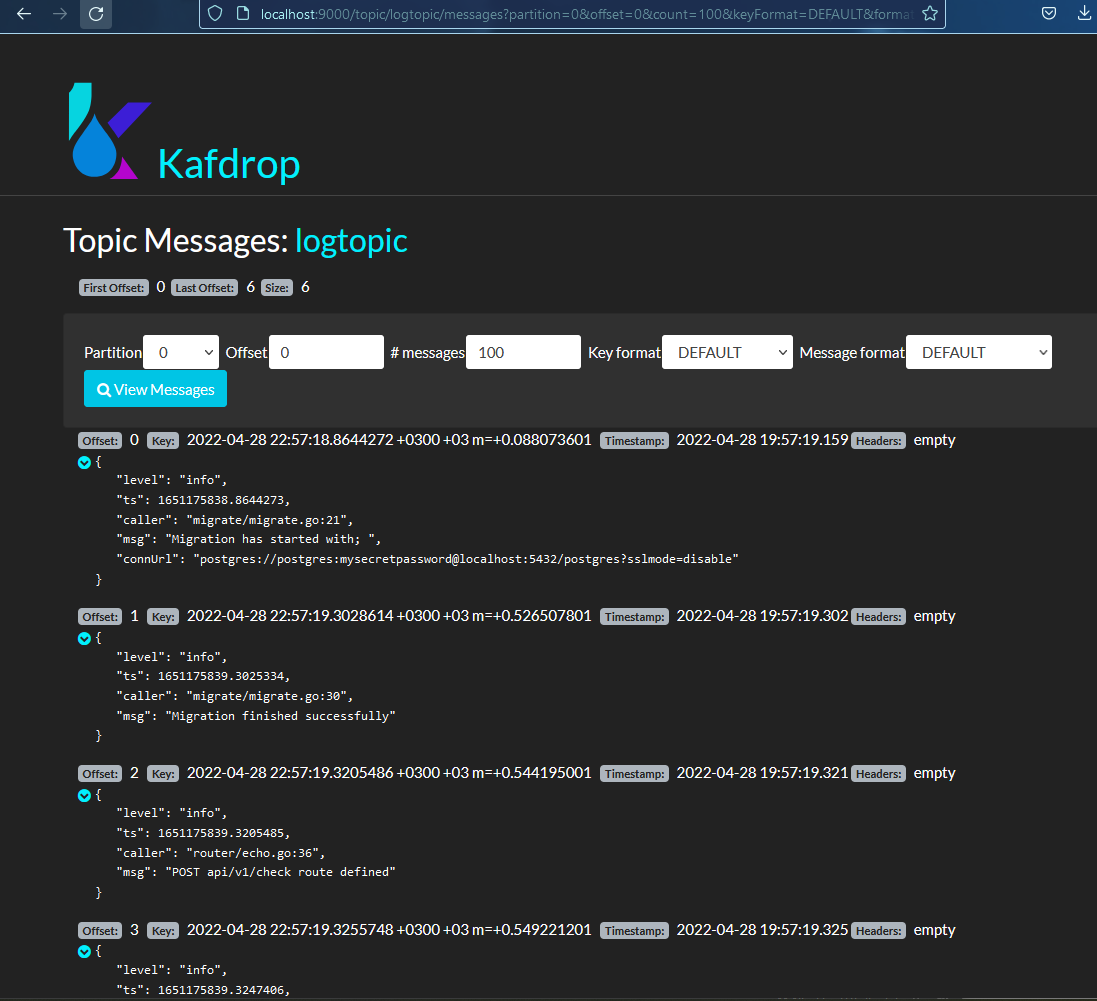
Uygulamamızı başlatıp http://localhost:9000 bağlandığımızda logtopic isimli topic in altında uygulamamızın loglarının yer aldığını görebilirsiniz. Bu logları Kafka Connect gibi araçlarla istediğiniz merkezi log yönetimi tooluna aktarımını gerçekleştirebilirsiniz.
Access Log Management
Access logları uygulamaya yapılan her türlü isteğin ve cevabının loglandığı loglardır. Serinin API Management yazısında bu konunun nasıl ele alınabileceği ile ilgili detaya ulaşabilirsiniz.
Serinin sonraki yazısı DB Migration ve RDBMS Entegrasyonu hakkında, buradan erişebilirsiniz.
Serinin tüm yazılarına aşağıdaki linkler aracılığıyla erişebilirsiniz.
- Golang ile Uçtan Uca Proje Yapımı Serisi
- Golang Configuration Management
- Golang Central Logging Management
- Golang DB Migration - RDBMS & ORM Integration
- Golang API Management
- Golang Message Broker - Object Mapping - Testing
Yukarıda değindiğimiz bütün kodlara https://github.com/mehmetcemyucel/blog/tree/master/demo adresinden erişebilirsiniz.